読んでいただきありがとうございます.
WordPressでの数式の表現力に限界を感じたため,
このブログをGithub Pagesに移行しようと思います.
移行先は,
nktmemo_ja
になります.徐々に最新の記事から移行しているのでしばらくかかります.
引き続きよろしくお願いします!
読んでいただきありがとうございます.
WordPressでの数式の表現力に限界を感じたため,
このブログをGithub Pagesに移行しようと思います.
移行先は,
になります.徐々に最新の記事から移行しているのでしばらくかかります.
引き続きよろしくお願いします!
追記(2016/07/22)
sample weightingによるPUClassificationも実装しました
– https://gist.github.com/nkt1546789/d4ffebb452fe738b8aaa8005fc08a068
任意の分類器を使えるのでこちらの方が良い気がします.
通常の2値分類問題では,正例と負例が与えられています. しかし扱う問題によっては,このようなデータを用意するのが困難な時があります. 例えば,抽出型のタスクです. 抽出型のタスクでは,抽出したい対象を正例と考えます. この場合の負例は「正例以外のデータ」と定義するほかありません. しかし,集めた正例に対し,それ以外のデータを負例と定義してしまうと, それ以外のデータに含まれる正例も負例として扱ってしまいます.
このように負例を定義するのが難しい場合には,正例とラベルなしデータから学習する枠組み,PU classificationが有用です. PU classificationについては,Elkan and Noto 2008を参照していただければと思うのですが,少しだけ解説しておきます. 3つの確率変数






と表せます.

では,以下のような正解データを考えましょう. 
このデータに対して,実際に与えられるのは以下のようなデータです. 
このデータに対して,まずは通常のロジスティック回帰を適用してみます. なお,今回は負例が多いので,交差確認法には正例側のF値を用います. 結果は以下のようになりました. 
ご覧のように,全て負例だと予測してしまいました. 次に,PU classificationを適用してみます. 
正例とラベルなしデータから,うまく分類境界を学習できていることがわかります.
デモ用のコードは以下に載せておきますのでぜひ試してみてください. ちなみに,非線形な分類境界を表現するためのrbfmodel_wrapper.py と PU Classificationのためのpuwrapper.py も合わせてDLしてください.
単語間には様々な関係があります. 今回は,単語間の関係をWord2Vecで学習させようと思います. Word2Vecにはアナロジーを捉えられるという話があります. あの有名な,king – man + woman = queen というやつですね. これは,king – man = queen – womanとも書けます. つまり,2語間の差が関係を表しており, この例だと,kingとmanの関係とqueenとwomanの関係が同じであると捉えることができます.
さて,Word2Vecで学習したベクトル表現を使うと,差ベクトルがうまいこと関係を表すと書きましたが, 必ずしもそうなっているとは限りません. 加えて,ユーザが扱いたい関係とWord2Vecで学習した関係が一致しているとも限りません. そこで,今回も例のごとく教師あり学習を使います. ユーザは教師データを通して,扱いたい関係をアルゴリズムに伝えることができます.
最初からあまり多くの関係を対象にするのはしんどいので,今回はis-a, has-a関係のみに着目します. これは,僕の理解では,柔道 is-a スポーツ,スポーツ has-a 柔道みたいなものだと思っています. まずはtraining dataを用意します. is-aとhas-aは反対の関係になっていると思うので,has-aのデータだけ用意します. この中には (スポーツ,野球)というhas-a関係を表す順序対がリストで格納されています. リスト内の順序対に対して差ベクトルを計算し,一つのデータとして扱います.
コードは以下のようになりました.
import training
from gensim.models import Word2Vec
import numpy as np
from sklearn.linear_model import LogisticRegressionCV
np.random.seed(1)
model=Word2Vec.load("/path/to/your/w2v_model")
data=[]
X=[]
y=[]
for w1,w2 in training.data:
if w1 in model and w2 in model:
data.append([w1,w2])
data.append([w2,w1])
X.append(model[w1]-model[w2])
X.append(model[w2]-model[w1])
y.append(1)
y.append(-1)
X=np.array(X)
y=np.array(y)
idx=np.random.permutation(len(y))
ntr=int(len(y)*0.7)
itr=idx[:ntr]
ite=idx[ntr:]
Xtr=X[itr]
ytr=y[itr]
Xte=X[ite]
yte=y[ite]
clf=LogisticRegressionCV().fit(Xtr,ytr)
ypred=clf.predict(Xte)
from sklearn import metrics
print metrics.accuracy_score(yte,ypred) # >>> 0.99502487562189057
今回は厳密な実験はせずに,簡単に性能を見てみました. テストデータに対して,99%の精度を出すことができました. 以下簡単なテストデータへの予測例です.
for j,i in enumerate(ite):
w1,w2=data[i]
if ypred[j]==1:
print w1,"has-a",w2
else:
print w1,"is-a",w2
# results:
ブルーベリー is-a 果物
動物 has-a モルモット
動物 has-a ワタボウシタマリン
スポーツ is-a スポーツ
登山 is-a スポーツ
ロデオ is-a スポーツ
動物 has-a ユーラシアカワウソ
スポーツ has-a フリーダイビング
競馬 is-a スポーツ
スポーツ has-a ゴルフ
...
いかがでしょうか?うまく狙った関係が分類できていると思います. とりあえずはうまくいきました!これで成功です! これがどこまで実用に耐えられるかはやってみないとわかりませんが…
前回:
の続きです.
まずは,前回のおさらい. 前回は,文書に対してはラベル付きデータが与えられており,単語についてはラベルなしデータが与えられているという設定を考えました. そして,文書と単語が同じ空間に存在すれば,半教師付き学習に帰着することを示しました. 詳しくは前回の記事を見ていただくとして,これからは半教師付き学習の設定で話を進めます.
今回は,前回の記事でいう単語ベクトル集合
その後,教師あり次元削減手法であるFisher Discriminant Analysis (FDA)を使って





なぜこのような処理をするかというと,Word2Vecのような教師なし学習では,必ずしも「望ましい結果」が得られるとは限りません. なぜなら,「望ましい結果」についての情報を一切与えていないからです. 今回の目的は文書分類+単語分類です. この目的に対して,Word2Vecが必ずしも望ましい結果を返すとは限らないのです.
そこで,教師あり次元削減を使います. FDAは,簡単にいうと,同じクラスに属するサンプルは近く,異なるクラスに属するサンプルは遠くなるよう,射影行列を学習します. ここでは,「望ましい結果」教師データとして与えるので,学習後の空間は分類という目的に対して望ましい空間になっていると期待できます.
さて,あとは対して面白いことはしていません.
前回と同じデータを使って実験をしました. 結果の出力には同様にwordcloudを使わせてもらいました.
ガールズ: 
ニュース・ゴシップ: 
エンタメ・カルチャー: 
おでかけ・グルメ: 
暮らし・アイデア: 
レシピ: 
カラダ: 
ビジネススキル: 
IT・ガジェット: 
デザイン・アート: 
雑学: 
おもしろ: 
定番: 
評価データがなくて定性的に評価するしかないのですが,前回と比べて,かなり改善されている気がします. 雑学とかおもしろ,定番なんかは定義がよくわからなくて判断しにくいですが,それ以外はうまく単語分類ができていると思います.
今回は,Word2Vec+教師あり次元削減 (FDA) を使って文書分類器を作成し,それを使って単語分類をしてみました. 結果として,このアプローチはなかなか良いと感じました. 文書分類,単語分類については,これでひと段落した感じがします. 本当は単語分類なんかはマルチラベル分類問題として解くべくなのかもしれませんが,あまりこの問題に執着してもあれなので. 次は要約や,トレンド抽出なんかをやっていきたいなあなんて思っています.
前回と今回はコードを載せていません. これはコードがなかなか複雑なためです. もし,見てみたいという方がいたら,コメントからでも,Twitterからでもなんでも良いので言ってください! 読んでいただき,ありがとうございました.
keywords: 文書分類 (document classification), 単語分類(word classification), Pointwise mutual information
文書へのラベリングと単語へのラベリングはどちらが簡単だろう? 例えば多くのニュースサイトではすでに文書は分類されている. しかし,単語が分類されているのは見たことがない. というより,そんなものを表に出してもあまり意味がないので表に出ていないのだろう. この状況を踏まえると,データをクロールする側からすると,ラベル付き文書データを入手するのは容易で, ラベル付き単語データを入手するのは困難だと言える.
いま,文書データをクロールして,検索エンジンを作ることを考えよう. 各文書にはラベルが付いている. このラベル情報を活かせないか? 例えばクエリにラベルが付いていれば,クエリと文書のラベルを見て,一致するものを出せばよい,あるいはそういう場合にスコアが高くなるように,検索エンジンのスコアを設計すれば良い. このように,単語へのラベリングはある程度需要があると推測される.
さて,今回やるのは,ラベル付き文書データを使って,単語分類をしようというもの. つまり,持っているものは,




ここで,もし単語と文書が同じ空間に存在すれば,文書分類器を使って単語分類ができると思われる. つまり,




簡単のために,

となる.さらに,「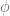

となる.というわけで,
さて,やらなければならないのは,
を学習する
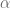 の決定
の決定
である.だいぶシンプルになったな.1に関しては死ぬほど研究されているので,その中から適用な手法を使うことにする. ここでは,PPMIを使って単語ベクトルを決定してみる.この辺は特に珍しくもないので,例えば以下を参照してください.
残る問題は2だ.とりあえずシンプルさを追求して,単語の出現回数を使うことにする.つまり,


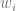
コードは後日載せます. やっていることは,PPMIを要素とした単語-文脈行列を作り,その各行を単語ベクトルとします. あとは↑の定式化通りに文書ベクトルを生成し,文書分類器を作ります. その後,単語ベクトルたちを分類器にかけます. 文書分類器には,ロジスティック回帰(sklearn.linear_model.LogisticRegressionCV)を用います. デフォルト設定です(アプローチの可能性を見たいだけなので).
データはnaverまとめからクロールしたものを使う. カテゴリとそれに対応するクロールした文書数を以下の表に示す. これが今回の訓練データ.
| カテゴリ | 文書数 |
|---|---|
| ガールズ | 600 |
| ニュース・ゴシップ | 976 |
| エンタメ・カルチャー | 480 |
| おでかけ・グルメ | 867 |
| 暮らし・アイデア | 737 |
| レシピ | 702 |
| カラダ | 708 |
| ビジネススキル | 558 |
| IT・ガジェット | 231 |
| デザイン・アート | 479 |
| 雑学 | 667 |
| おもしろ | 584 |
| 定番 | 257 |
総異なり語数は14767件で,これが今回の分類対象となる. さて,結果はただ単語を羅列してもおもしろくないので,wordcloudを使おうと思う. これについては以下を参考にしました,ありがとうございます.












該当単語なし
今回はラベル付き文書データから文書分類器を学習し,それを単語分類に使用してみた. 結果は定性的に測るしかないが,うまくいっているところはあるのでアプローチは悪くないのかなと思う. 定番に該当がないのは定番だからなのだろうか?笑 ただ,もっと分類器をチューニングしたほうが良い気がする. いまはただロジスティック回帰にぶん投げているだけなので.
次回は,教師あり次元削減,具体的にはFisher Discriminant Analysis (FDA)をかけてみます. いまは生の単語-文脈行列を使っているので,情報をもっと圧縮させて次元を削減しようと思います. さらに,教師ありデータを使うことで,同じラベルを持つものは近くなり,異なるラベルを持つものは遠くなるよう次元削減後の空間を学習します(正確には射影行列). まぁとりあえずいいんではなかろうか.
分類問題において,非線形な決定境界を表現するための一つの方法に,RBF Kernel Modelがあります. これは,入力

コードはGistに載せてあります:
https://gist.github.com/nkt1546789/e41199340f7a42c515be
使い方は,例えばsklearnのLogisticRegressionに適用したい場合は,
clf=RbfModelWrapper(LogisticRegression()).fit(X,y)
同様にRidgeに適用したい場合は,
clf=RbfModelWrapper(Ridge()).fit(X,y)
ちなみにGridSearchもできるようになっています:
gs=GridSearchCV(RbfModelWrapper(Ridge()),param_grid={"gamma":np.logspace(-2,0,9),"alpha":[1,10,100]}).fit(X[itr],y[itr])
教師ありデータ

ラプラス正則化の基本的なアイデアは,「似ているものは同じラベルを持つ」というもの. 具体的には,類似度行列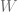
最後の項がラプラス正則化項. この項は結局ラプラス行列というもので表されるのでラプラス正則化と呼ばれている.
ここで,非線形な決定境界を表現するために,
コードは以下のようになった.
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| from numpy import linalg,random | |
| from sklearn.base import BaseEstimator | |
| from sklearn import datasets,metrics | |
| class LRRidge(BaseEstimator): | |
| def __init__(self,alpha=1.,beta=1.,gamma=10.,k=10): | |
| self.alpha=alpha | |
| self.beta=beta | |
| self.gamma=gamma | |
| self.k=k | |
| def fit(self,Xl,yl,Xu): | |
| self.X=np.r_[Xl,Xu] | |
| #self.X=self.X[random.permutation(len(self.X))] | |
| self.X2=np.c_[np.sum(self.X**2,1)] | |
| Xl2=np.c_[np.sum(Xl**2,1)] | |
| Xu2=np.c_[np.sum(Xu**2,1)] | |
| Phil=np.exp(-self.gamma*(Xl2+self.X2.T-2*Xl.dot(self.X.T))) | |
| Phiu=np.exp(-self.gamma*(Xu2+self.X2.T-2*Xu.dot(self.X.T))) | |
| Phiu2=np.c_[np.sum(Phiu**2,1)] | |
| d=Phiu2+Phiu2.T-2*Phiu.dot(Phiu.T) | |
| p=np.c_[np.sort(d,axis=1)[:,self.k+1]] | |
| W=d<=p | |
| W=(W+W.T)!=0 | |
| D=np.diag(np.sum(W,axis=1)) | |
| L=D-W | |
| n_features=Phil.shape[1] | |
| self.theta=linalg.pinv(Phil.T.dot(Phil)+self.alpha*np.identity(n_features)+self.beta*Phiu.T.dot(L).dot(Phiu)).dot(Phil.T).dot(yl) | |
| return self | |
| def predict(self,X): | |
| X2=np.c_[np.sum(X**2,1)] | |
| Phi=np.exp(-self.gamma*(X2+self.X2.T-2*X.dot(self.X.T))) | |
| return (Phi.dot(self.theta)>=0)*2-1 | |
| # demo | |
| random.seed(1) | |
| n=500 | |
| X,y=datasets.make_circles(n_samples=n,factor=.5,noise=.05) | |
| #X,y=datasets.make_moons(n_samples=n,noise=.05) | |
| y=y*2-1 | |
| nl=2 # number of labeled samples | |
| idx=random.permutation(len(X)) | |
| il=idx[:nl]; iu=idx[nl:]; | |
| Xl=X[il]; Xu=X[iu]; | |
| yl=y[il]; yu=y[iu]; | |
| clf=LRRidge().fit(Xl,yl,Xu) | |
| ypred=clf.predict(X) | |
| yupred=clf.predict(Xu) | |
| print "Accuracy (LRRidge):",metrics.accuracy_score(yu,yupred) | |
| from sklearn.linear_model import RidgeClassifierCV | |
| gamma=10. | |
| X2=np.c_[np.sum(X**2,1)] | |
| Phi=np.exp(-gamma*(X2+X2.T-2*X.dot(X.T))) | |
| clf=RidgeClassifierCV().fit(Phi[il],yl) | |
| yupred2=clf.predict(Phi[iu]) | |
| print "Accuracy (Ridge):",metrics.accuracy_score(yu,yupred2) | |
| colors=np.array(["r","b"]) | |
| plt.figure(figsize=(12,6)) | |
| plt.subplot(121) | |
| plt.scatter(Xu[:,0],Xu[:,1],c="w",s=20) | |
| plt.scatter(Xl[:,0],Xl[:,1],color=colors[(1+yl)/2],s=100) | |
| plt.subplot(122) | |
| plt.scatter(X[:,0],X[:,1],color=colors[(1+ypred)/2]) | |
| plt.tight_layout() | |
| plt.show() |
実行結果はこんな感じ. 左が訓練データで赤と青がラベル付きデータで白い点がラベルなしデータ. このように,たった2つの教師ありデータから正しく分類ができている.


ラプラス正則化は目的関数に一つ項を加えるだけで, 教師なしデータも活用できるのでお手軽で性能も素晴らしいので是非使ってみてください. 課題としてはパラメータチューニングがある. 教師ありデータが十分にあれば,交差検定ができるが,この例では2つしかないので最適なパラメータを得るのは難しい. それと,RBFカーネルモデルにすべてのデータ点を使っているものポイント.
HTMLから本文あるいはコンテンツを抽出したいという需要はかなりあると思う. この問題に対して,機械学習的なアプローチをしているdragnetというものがある(ソースは以下).
dragnetはHTMLをまずblockと呼ばれる単位に分割する. その後,そのブロックが本文であるかないかのラベルをつける. このようなラベル付きデータを用いて,分類器をトレーニングしている. データも以下で公開されていて,自由に追加してコミットすることができる.
分類器にはロジスティック回帰が使われているようだ. ロジスティック回帰は,ブロックが本文かどうかという確率を返すので,この閾値を自分なりにいじることでカスタマイズすることもできる. しかし,オリジナルのソースではこの部分がおかしなことになっている. というのも,dragnet.cotent_extractor.set_thresholdで閾値を設定できるのだが, 閾値で区切るところでdragnet.cotent_extractor._block_model.predictに対して閾値で区切っている. これはすごくおかしなことでpredictは0か1を吐くので閾値で切るというのが実際は機能していない.
というわけでフォークしてそこを書き換えてみた. 以下にそのリポジトリがある(なぜかプルリクが投げれなかった).
オリジナルを使う場合は以下の関数を使用すると良い.
| from dragnet import content_extractor | |
| classes=list(content_extractor._block_model.classes_) | |
| positive_idx=classes.index(1) | |
| def extract(html,block=False,threshold=0.2): | |
| features,blocks=content_extractor.make_features(html) | |
| scores=content_extractor._block_model.predict_proba(features)[:,positive_idx] | |
| if block: | |
| return [block for i,block in enumerate(blocks) if scores[i]>=threshold] | |
| return " ".join([block.text for i,block in enumerate(blocks) if scores[i]>=threshold]) | |
| # demo | |
| import requests | |
| url="your url" | |
| html=requests.get(url).content | |
| print extract(html) |
このようなcontent extractor共通の悩みだと思うが, ニュースサイトとかではうまくいくけど,動画サイトや,特殊なサイトでは動かないというケースがある. そのようなケースでも閾値で対応できるかもしれないけど,試していない. とりあえず.dragnetは素晴らしいので是非使ってみてください.
追記(2015/07/30):pull requestを投げました.マージされればきちんとthresholdを設定できます.
前回:
の続き.というかこっちを先にするべきだった. 引き続きlivedoorニュースコーパスを使う. クラス数は9で総文書数は7356件. 今回の対象はタイトルと全文. なので各文書がある程度長いことを想定 (次回はここをタイトルのみにして短い文書に対する分類結果も出してみる).
前回はword2vecを使ったが, 今回は普通にBag-of-WordsモデルとそれにTFIDFで重み付けをしたものを比較してみる. 実験の設定は前回と同じなので,前回の結果とも比較できる. 各文書がある程度長いのでBOWでもいい結果が出るだろうと予測したが,どうなんだろうか.
結果は以下のようになった.
| BOW | BOW+TFIDF | w2v |
| 0.95 (0.004) | 0.95 (0.004) | 0.85 (0.007) |
検定はしていないが,おそらくBOW (+ TFIDF)はword2vecを使ったモデルよりも性能が良いと言っていいだろう. 以下の要因が考えられる.
次回からは,このあたりを制限していって,結果がどう変わるかを見ていこうと思う. あと,word2vecをこのコーパスでトレーニングしてもいいかも.
word2vecの応用として文書分類,ここではニュース分類をやってみました. データはlivedoorニュースコーパスを使いました. あと,wikipediaのデータで学習させたモデルを使いました.
bag-of-wordsを用いた場合は以下で議論されています.
さて,今回はword2vecを使って文書分類に挑戦してみます. word2vecにより,単語空間は有限次元ベクトル空間で表現されています. 単語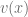

さて,最もシンプルな文書ベクトルは以下のようになるだろう.

これをモデル1とする.
次に,以下のような重み付きバージョンを考える.

この重み
モデル1はすぐに構築できるが,モデル2の重みを何にしようか迷う. 今回のタスクは文書分類なのだから,クラス分類において重要な単語には大きな重みをつけるべきだろう. そう考えると,以下の重み関数はどうだろうか.

ここで


さて,まずは文書を形態素解析するのだが(形態素解析を使わないバージョンは次に書こうと思う), 辞書には最近流行りのneologdを使う.
ライブドアニュースコーパスのディレクトリ構成は以下のようになっていることを想定.
livedoor_corpus/ dokujo-tsushin/ it-life-hack/ kaden-channel/ livedoor-homme/ movie-enter/ peachy/ smax/ sports-watch/ topic-news/
なお,カテゴリ数は9で総文書数は7376であった. 分類器にはロジスティック回帰を用いた.
以下に実験結果を示す.
| uniform | tficf |
| 0.85 (0.01) | 0.52 (0.03) |
tficfが重み付けを行った結果だ.ものすごく悪い. 一方重み付けを行わないモデル (uniform) はかなりいい性能を発揮している. 重み付けによりここまで性能が落ちるとは思わなかった. 何かバグがないか追求してみるが,今のところword2vecで学習した単語空間をそのまま使っても特に問題はなさそうだ. それにしても上のqiitaの記事ではBOW+kNNというシンプルな組み合わせながら精度が89%と報告されている. これはおそらく文書分類というタスクでは,文書が多数の単語を含むのでBOWでも十分にそれを表現できているため,と解釈できる. 逆に,一つの文書が短かったり,単語そのものを分類しなければならないようなタスクでは,word2vecの真価が発揮されるのではないかと思う.
単語分類については以下に簡単な例がある.
実は,短い文書においては,TFICFの有効性を確認した.よって長い文書でも動くはずなのだが,今回は動かなかった. というわけでバグを探すのと,word2vecの他の応用も考えてみる.
実験に使ったコードはGistに置いておくので,気が向いたら試してみてください:
| # coding: utf-8 | |
| import os,codecs,re,pickle | |
| import numpy as np | |
| from gensim.models import word2vec | |
| from gensim import matutils | |
| basepath="/path/to/corpus_dir" | |
| dir_names=["dokujo-tsushin","it-life-hack","kaden-channel","livedoor-homme","movie-enter","peachy","smax","sports-watch","topic-news"] | |
| def make_data(model_filename,data_filename,tokenize): | |
| model=word2vec.Word2Vec.load(model_filename) | |
| X=[] | |
| y=[] | |
| for category,dir_name in enumerate(dir_names): | |
| dir_name=os.path.join(basepath,dir_name) | |
| for filename in os.listdir(dir_name): | |
| filename=os.path.join(dir_name,filename) | |
| text=codecs.open(filename,"r","utf-8").readlines()[2:] # for removing the date (1st line) | |
| text=u"".join(text) | |
| this_vector=np.array([matutils.unitvec(model[word]) for word in tokenize(text) if word in model]).mean(axis=0) | |
| X.append(this_vector) | |
| y.append(category) | |
| X=np.array(X) | |
| y=np.array(y) | |
| data={"data":X,"target":y} | |
| pickle.dump(data,open(data_filename,"wb")) | |
| def evaluate(data_filename,classifier,n_runs=30,verbose=False): | |
| data=pickle.load(open(data_filename)) | |
| X=data["data"] | |
| y=data["target"] | |
| ntr=np.int32(len(y)*0.7) | |
| accuracies=np.zeros(n_runs) | |
| for i in xrange(n_runs): | |
| idx=np.random.permutation(len(y)) | |
| itr=idx[:ntr] | |
| ite=idx[ntr:] | |
| classifier.fit(X[itr],y[itr]) | |
| accuracy=classifier.score(X[ite],y[ite]) | |
| if verbose: | |
| print "accuracy:",accuracy | |
| accuracies[i]=accuracy | |
| return accuracies | |
| if __name__ == '__main__': | |
| make_data("/path/to/w2v_model", | |
| "data.pkl", | |
| tokenize) | |
| from sklearn.linear_model import LogisticRegressionCV | |
| accuracies=evaluate("data.pkl", | |
| LogisticRegressionCV(), | |
| verbose=True) | |
| print "accuracies: {0}, std: {1}".format(np.mean(accuracies),np.std(accuracies)) |



